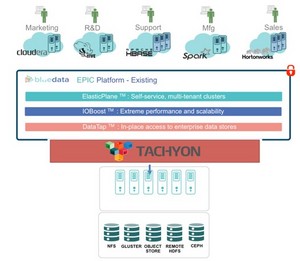
MOUNTAIN VIEW, CA--(Marketwired - Feb 3, 2015) - BlueData, the pioneer in Big Data private clouds, today announced a technology preview of the Tachyon in-memory distributed storage system as a new option for the BlueData EPIC platform. Together with the company's existing integration with Apache Spark, BlueData supports the next generation of Big Data analytics with real-time capabilities at scale, which allows organizations to realize value from their Big Data that wasn't before possible. In addition, this new integration enables Hadoop, Hbase virtual clusters, and other applications provisioned in the BlueData platform, to take advantage of Tachyon's high performance in-memory data processing.
Enterprises need to be able to run a wide variety of Big Data jobs such as trading, fraud detection, cybersecurity and system monitoring. These high performance applications require the ability to run in real-time and at scale in order to provide true value to the business. Existing Big Data approaches using Hadoop are relatively inflexible and do not fully meet the business needs for high speed stream processing. New technologies like Spark, which offers 100X faster data processing, and Tachyon, which offers 300X higher throughput, overcome these challenges.
However, incorporating these technologies with existing Big Data platforms like Hadoop requires point integrations on a cluster-by-cluster basis, which makes it manual and slow. With this preview, BlueData is streamlining infrastructure by creating a unified platform that incorporates Tachyon. This allows users to focus on building real-time processing applications rather than manually cobbling together infrastructure components.
"Big Data is about the combination of speed and scale for analytics. With the advent of the Internet of Things and streaming data, Big Data is helping enterprises make more decisions in real time. Spark and Tachyon will be the next generation of building blocks for interactive and instantaneous processing and analytics, much like Hadoop MapReduce and disk-based HDFS were for batch processing," said Nik Rouda, senior analyst of Enterprise Strategy Group. "By incorporating a shared in-memory distributed storage system in a common platform that runs multiple clusters, BlueData streamlines the development of real-time analytics applications and services."
"We are thrilled to welcome BlueData into the Tachyon community, and we look forward to working with BlueData to refine features for Big Data applications," said Haoyuan Li, co-creator and lead of Tachyon.
The BlueData platform also includes high availability, auto tuning of configurations based on cluster size and virtual resources, and compatibility with each of the leading Hadoop distributions. Customers who deploy BlueData can now take advantage of these enterprise-grade benefits along with the memory-speed advantages of Spark and Tachyon for any Big Data application, on any server, with any storage.
"First generation enterprise data lakes and data hubs showed us the possibilities with batch processing and analytics. With the advent of Spark, the momentum has clearly shifted to in-memory and streaming with emerging use cases around IoT, real-time analytics and high speed machine learning. Tachyon's appealing architecture has the potential to be a key foundational building block for the next generation logical data lake and key to the adoption and success of in-memory computing," said Kumar Sreekanti, CEO and co-founder of BlueData. "BlueData is proud to deliver the industry's first Big Data private cloud with a shared, distributed in-memory Tachyon file system. We look forward to continuing our partnership with Tachyon to deliver on our mission of democratizing Big Data private clouds."
Watch a demo video of the integration of BlueData and Tachyon: http://youtu.be/xxz8uqRVQYQ. For a more technical deep dive, read BlueData Chief Architect Tom Phelan's blog: http://bit.ly/1F17aay
Visit BlueData at Strata + Hadoop World in San Jose, CA from February 17-20 at booth #1521 to see a live demo.
Note to editor: BlueData will be speaking at the Strata + Hadoop World Solutions Showcase, Thursday, February 19 from 1:30 - 1:40 p.m. on how a leading telecommunications company used BlueData to spin up local, on demand Hadoop and Spark clusters to enable agile deployment of Big Data tools and technologies. For more information, visit http://strataconf.com/big-data-conference-ca-2015
About BlueData
BlueData is the pioneer in Big Data private cloud. The company is democratizing Big Data by streamlining and simplifying Big Data infrastructure and eliminating complexity as a barrier to adoption. With its EPIC software platform, enterprises can now build agile, secure and cost-effective Big Data deployments that deliver value in days instead of months and at a cost savings of 50%-75% compared to traditional approaches. With BlueData, enterprises of all sizes can create a public cloud-like experience from their on-premise environments and get the same value out of their Big Data as companies like Google, Facebook and Yahoo at a fraction of the cost and with far fewer resources. Based in Mountain View, CA, BlueData is founded by a highly experienced team from VMware, Akamai, Intel and SGI and backed by industry luminaries from Silicon Valley. For more information, contact info@bluedata.com.
Contact Information:
Media Contact
Kristina Richmann
Trainer Communications
925.271.8216